Er zijn vele boeken geschreven over business intelligence (BI). Om te achterhalen welke terminologie het vaakst wordt gebruikt binnen dit specialisme verken ik in deze blog de inhoud van meerdere BI boeken. Verder ga ik aan de hand van de wet van Zipf na in hoeverre de teksten volgens de principes van de minste inspanning zijn opgesteld. Na het lezen van deze blog kun je dit ook toepassen op je eigen documenten.
Boekenlijst
Uiteraard is ook voor deze analyse data nodig: de documenten die de basis vormen van deze blog waren vrij te downloaden op het internet. De gedownloade .pdf-bestanden zijn opgeslagen als .txt-bestand om ze makkelijk in te kunnen laden in Tableau. De volgende documenten zijn gebruikt:
- Business intelligence (Solomon Negash)
- The BI framework (Logica)
- Getting started with data-warehousing and business intelligence (IBM)
- Introduction to data warehousing and business intelligence (Jensen, Pedersen en Thomsen)
- Microsoft business intelligence (Peter Myers)
- Microsoft business intelligence for dummies (Ken Withee)
- The bumper book of business intelligence (Matillion)
Data inladen
Binnen de tekstbestanden worden woorden gescheiden door spaties; Tableau scheidt de woorden naar aparte kolommen middels deze spaties. Alle boeken kunnen vervolgens middels een union onder elkaar worden gezet. Alle kolommen met woorden kunnen nu onder elkaar worden gezet middels een pivot. De dataset is nu klaar om te worden opgeschoond.
Data opschonen
Het opschonen van de data is hier gedaan met reguliere expressies (zie link: werkboek). Met reguliere expressies kan Tableau bepaalde tekstpatronen herkennen. Er zijn expressies aangemaakt om alle tekst over te houden (Figuur 1) en om alle woorden met een koppelteken ertussen te behouden. Ter illustratie: de tekst “double-clicking.” wordt met deze expressies omgezet in double-clicking; “[BI] wordt vervangen door BI en cellen met alleen symbolen (zoals ..—, == of :///) worden met deze expressie omgezet naar inhoudsloze cellen die met een extract filter uit de dataset verwijderd kunnen worden. Op deze manier blijven alle leestekens en getallen achterwege en is de dataset klaar voor analyse.

Figuur 1: voorbeeld van een van de ingezette reguliere expressies
De wet van Zipf
Na het opschonen van de data vroeg ik me af hoe goed de leesbaarheid van deze documenten is. George Kingsley Zipf geloofde dat de moeite die onderlinge communicatie kost, afhangt van twee factoren: de spreker/schrijver en de luisteraar/lezer. Het kost de schrijver de minimale inspanning als diegene in zo min mogelijk woorden het verhaal kan vertellen; tegelijkertijd kost het de lezer de minste moeite als de tekst juist veel specifiek woordgebruik bevat. Zipf veronderstelde dat het compromis tussen de zender en de ontvanger leidde tot de huidige staat van onze taal (zie ook het boek: Human Behavior and the Principle of Least Effort: An Introduction to Human Ecology). Onderzoek naar de voorkomens van woorden in enorme hoeveelheden tekst leverde een aantal interessante inzichten op. De 20 meest voorkomende woorden in de Engelse taal zijn bijvoorbeeld: the, of, and, to, a, in, that, it, is, was, I, for, on, you, he, be, with, as, by en at (zie link: wordcount.org). Verder bleek er ook een interessante relatie tussen het aantal voorkomens en de rangschikking van de woorden op basis van het aantal voorkomens in het Engelse taalgebruik: het bleek een extreme rechts-scheve verdeling van voorkomens te zijn (Figuur 2). Het lijkt dat deze documenten tezamen inderdaad volgens de principes van de minste inspanning zijn opgesteld.
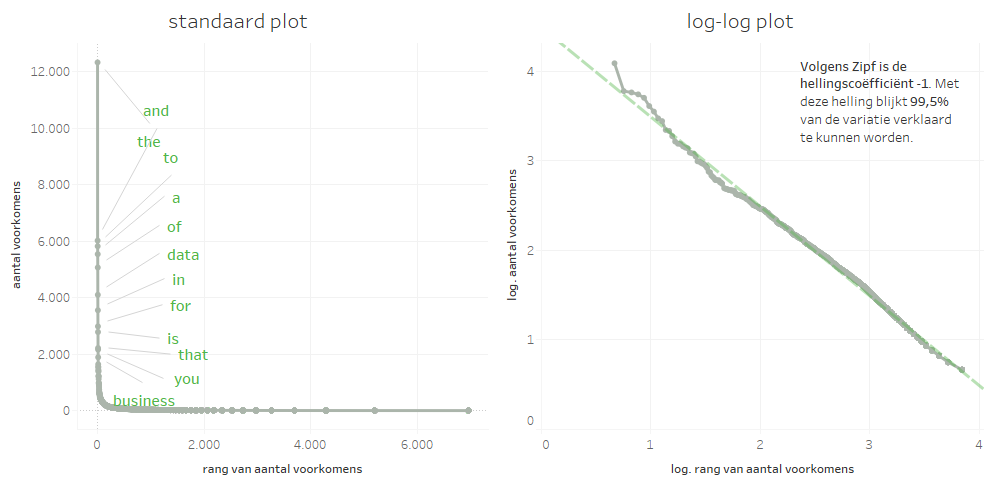
Figuur 2: de wet van Zipf en de rechts-scheve verdeling van woorden in BI-documentatie
Overigens geldt deze duimregel voor (vrijwel) alle andere talen. In 2010 publiceerden onderzoekers dat er binnen 10 talen een vergelijkbare relatie bestaat, maar dan voor de betekenis van woorden en de woordlengte (zie link: Piantadosi et al.).
Terminologie Business Intelligence
De tweede analyse in deze blog gaat over het maken van een woordenwolk (word cloud). Hiermee kan men achterhalen welke terminologie past bij het domein van business intelligence. Allereerst houden we de 50 meest voorkomende woorden uit de Engelse taal buiten de woordenwolk – deze woorden zijn allen erg gemeen en zouden zo de woordenwolk vervuilen met woorden die slechts gebruikt worden om woorden met daadwerkelijke inhoud te verbinden. Ik heb de top 50 (zie link: Oxford English Corpus) in een excelbestand opgeslagen en vervolgens gekoppeld aan het Tableau data-extract middels een cross-data base join op reguliere expressies (zie link: werkboek). Er is nu een kolom aan de dataset toegevoegd die op regelniveau ofwel een woord vanuit de top 50 presenteert, of de waarde Null presenteert wanneer het woord niet in de top 50 voorkomt. Door hierna een dimensiefilter toe te voegen waarbij Null wordt behouden, is de top 50 uit de dataset weggevangen. In Figuur 3 is te zien om welke woorden het gaat en welke positie ze innemen in de BI-documenten.
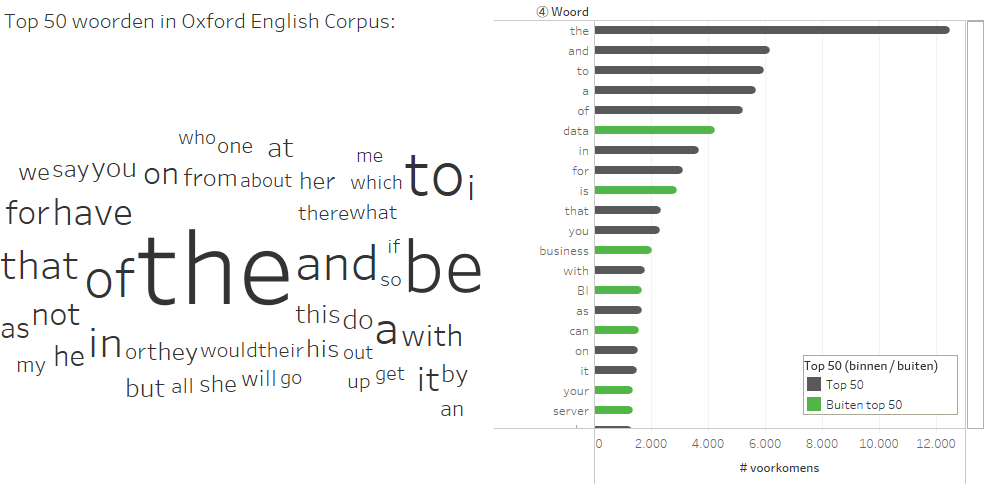
Figuur 3: de 50 meest voorkomende woorden in de Engelse taal helpen om informatieve woorden te verbinden
Word Cloud
We zijn klaar voor de laatste stap: de word cloud! We behouden de top 100 woorden op basis van het aantal voorkomens en we maken de visualisatie in Tableau (Figuur 4). Zo valt in één oogopslag te zien dat het in dit vakgebied allemaal draait om het verkrijgen en delen van inzicht uit data.
Zien, begrijpen, doen!

Figuur 4: onze BI-woordenwolk
Wil je ook eens de leesbaarheid van jouw eigen documenten toetsen, of een woordenwolk maken die aansluit bij jouw eigen domein? Download dan een gratis proefversie van Tableau en ervaar zelf de kracht van Tableau.